
云霄烟厂家生产视频
有问题请联系
更新时间:
云霄烟厂家生产视频《今日汇总》
云霄烟厂家生产视频2025已更新(2025已更新)
云霄烟厂家生产视频《今日汇总》2025已更新(今日/推荐)
云霄烟厂家生产视频
云霄烟厂家生产视频
7天24小时人工电话为您服务、云霄烟厂家生产视频服务团队在调度中心的统筹调配下,泊寓智能锁线下专业全国及各地区售后人员服务团队等专属服务,整个报修流程规范有序,后期同步跟踪查询公开透明。
所有售后团队均经过专业培训、持证上岗,所用产品配件均为原厂直供,
云霄烟厂家生产视频
泊云霄烟厂家生产视频全国服务区域:
云霄烟厂家生产视频受理中心
上海市(浦东新区、徐汇区、黄浦区、杨浦区、虹口区、闵行区、长宁区、普陀区、宝山区、静安区、闸北区、卢湾区、松江区、嘉定区、南汇区、金山区、青浦区、奉贤区)
北京市(东城区、西城区、崇文区、宣武区、朝阳区、丰台区、石景山区、海淀区、门头沟区、房山区、通州区、顺义区、昌平区、大兴区)
成都市(锦江区,青羊区,金牛区,武侯区,成华区,龙泉驿区,青白江区,新都区,温江区,双流区,郫都区,金堂县,大邑县,蒲江县,新津县,都江堰市,彭州市,邛崃市,崇州市)
长沙市(芙蓉区,天心区,岳麓区,开福区,雨花区,望城区,长沙县,宁乡市,浏阳市)
北京、上海、天津、重庆、南京、武汉、长沙、合肥、成都、南宁、杭州、广州、郑州、太原、济南、海口、哈尔滨、昆明、西安、福州、南宁、长春、沈阳、兰州、贵阳、湖州、南昌、深圳、东莞、珠海、常州、宁波、温州、绍兴、南通、苏州、张家港、徐州、宿迁、盐城、淮安、淮南、南通、泰州、昆山、扬州、无锡、北海、镇江、铜陵、滁州、芜湖、青岛、绵阳、咸阳、银川、嘉兴、佛山、宜昌、襄阳、株洲、柳州、安庆、黄石、怀化、岳阳、咸宁、石家庄、桂林、连云港、廊坊、大连、大庆、呼和浩特、乌鲁木齐、鞍山、齐齐哈尔、荆州、烟台、洛阳、柳州、
梁文锋参与著作!DeepSeek最新论文介绍新机制 可使AI模型进一步降本增效
2月18日,DeepSeek团队发布一篇论文介绍了新的注意力机制NSA(Natively Sparse Attention,原生稀疏注意力机制)。
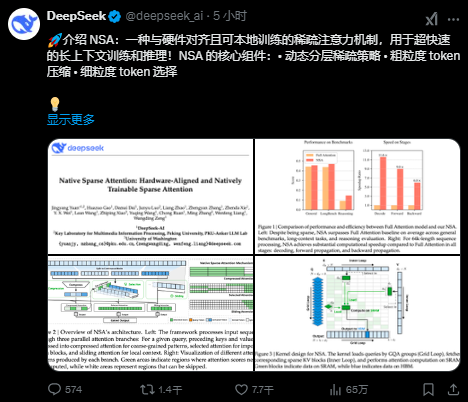
NSA专为长文本训练与推理设计,能利用动态分层稀疏策略等方法,通过针对现代硬件的优化设计,显著优化传统AI模型在训练和推理过程中的表现,特别是提升长上下文的推理能力,在保证性能的同时提升了推理速度,并有效降低了预训练成本。
DeepSeek创始人梁文锋现身论文著作者之中,在作者排名中位列倒数第二。

其他研究人员来自DeepSeek、北大和华盛顿大学,其中第一作者Jingyang Yuan(袁景阳)是在DeepSeek实习期间完成的这项研究。
资料显示,袁景阳目前为北京大学硕士研究生。他的研究领域包括大型语言模型(LLM)、人工智能在科学中的应用(AI for Science)。他是DeepSeek-V3技术报告的主要作者之一,还参与了DeepSeek-R1项目,该项目旨在通过强化学习激励大型语言模型的推理能力。
在论文中,DeepSeek团队表示,随着大型语言模型的发展,长上下文建模变得越来越重要,但传统注意力机制的计算复杂度随着序列长度的增加而呈平方级增长,成为制约模型发展的关键瓶颈。
NSA便是为高效处理长上下文任务而生的一种技术路径,其核心创新在于:
1)动态分层稀疏策略:结合粗粒度的Token压缩和细粒度的Token选择,既保证全局上下文感知,又兼顾局部信息的精确性。
2)硬件对齐与端到端训练:通过算术强度平衡的算法设计和硬件优化,显著提升计算速度,同时支持端到端训练,减少预训练计算量。
实验表明,NSA不仅在通用任务和长上下文任务中表现出色,还在链式推理等复杂任务中展现了强大的潜力,且推理速度加快。在通用基准测试、长文本处理以及基于指令的推理任务中,NSA的表现均能达到甚至超越传统全注意力(Full Attention)模型的水平,其以性价比极高的方式,罕见地在训练阶段应用稀疏性,在训推场景中均实现速度的明显提升,特别是在解码阶段实现了高达11.6倍的提升。
通过高效的长序列处理能力,NSA使模型能够直接处理整本书籍、代码仓库或多轮对话(如千轮客服场景),扩展了大语言模型在文档分析、代码生成、复杂推理等领域的应用边界。例如,Gemini 1.5 Pro已展示长上下文潜力,NSA可进一步降低此类模型的训练与推理成本。
本文转载自“财联社”,智通财经编辑:刘家殷。